Token Sparse Attention
Published:
Token Sparse Attention introduces a dynamic and complementary token-level sparsification mechanism for the long-context inference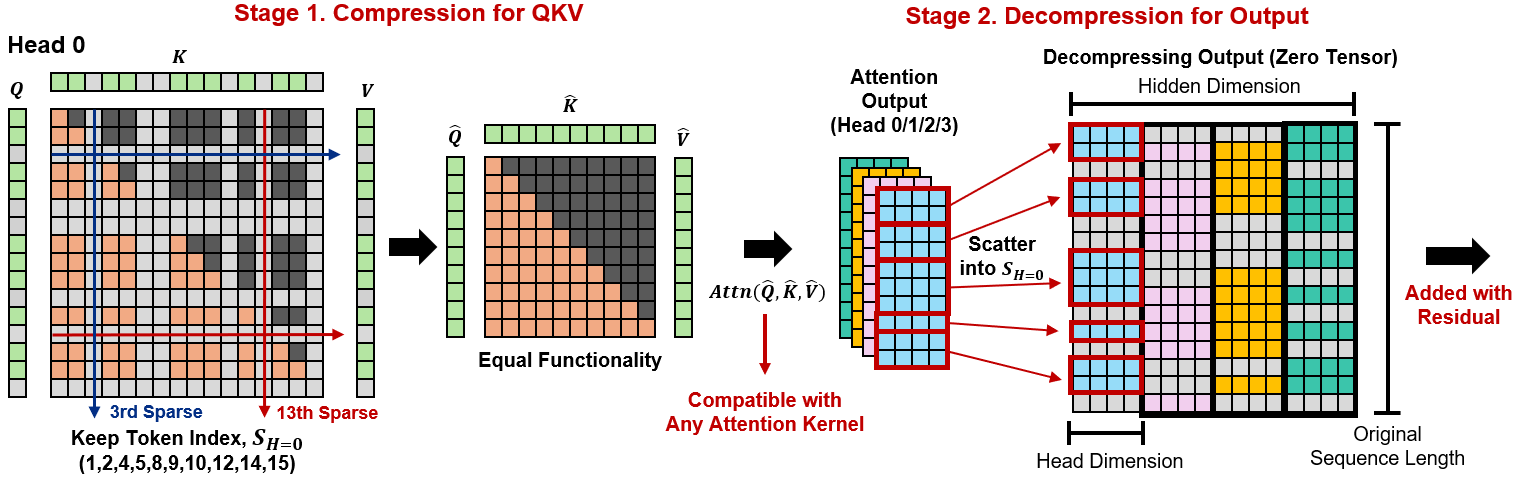

Published:
Token Sparse Attention introduces a dynamic and complementary token-level sparsification mechanism for the long-context inference
Published:
[3rd Place] The goal of this Computer Engineering Challenge is to maximize the inference speed while maintaining the accuracy of large-scale language models under limited memory and computing resources. 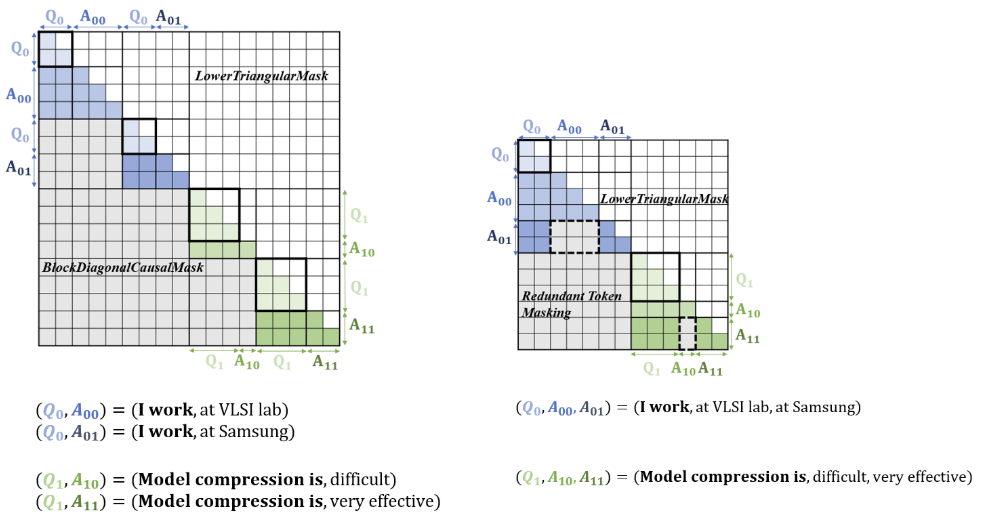
Published:
SqueezeBits team and collaborator SNU-VLSI lab have successfully developed Mobile Stable Diffusion by compressing the Stable Diffusion v2.1 model to run on Galaxy S22 device.