
2023 Samsung Computer Engineering Challenge (SAIT)
Published:
Overview
The 2023 Samsung Computer Engineering Challenge tasked participants with minimizing LLM inference latency on a fixed hardware platform while maintaining accuracy on the HellaSwag benchmark.
- Model: LLaMA-33B
- Task: Full HellaSwag dataset evaluation (~10k questions, 40k Q+A pairs)
- Hardware: Intel Xeon Gold 32 vCPUs + 360GB RAM + V100 32GB × 4
Our team proposed Redundant Token Sharing combined with kernel-level optimizations, achieving a 7.86× speedup over the lm-eval baseline while fully reproducing original model accuracy.

Key Idea: Redundant Token Sharing
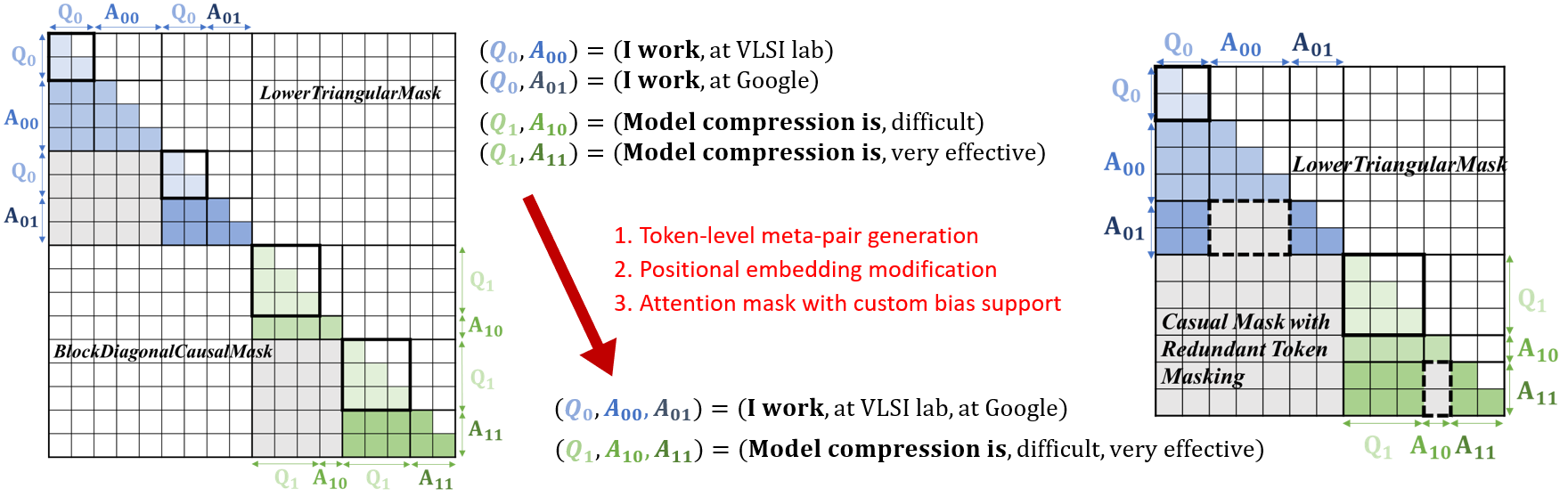
Standard HellaSwag evaluation builds 4 separate Q + Aᵢ pairs per question and runs 4 independent model forwards. Since the question Q is identical across all 4 pairs, this repeats the compute-heavy QKV projection, attention, and FFN for the shared Q tokens on every forward pass.
Our approach replaces 4 separate forwards with a single forward over one meta-pair Q + A₀, A₁, A₂, A₃. By forwarding Q only once, we reduce total sequence length by 1.89×, which translates to a ~4× reduction in attention compute (O(L²)).
| Count | Min | Max | Mean | Std | |
|---|---|---|---|---|---|
| len(Q) | 40k | 12 | 118 | 56 | 20 |
| len(A) | 40k | 2 | 98 | 33 | 16 |
| len(Pair) | 40k | 18 | 170 | 89 | 33 |
| len(Meta-pair) | 10k | 42 | 368 | 189 | 72 |
Three modifications were required to make the meta-pair forward equivalent to 4 separate forwards:
- Token-level meta-pair generation: concatenate
Q + A₀A₁A₂A₃into a single sequence within the maximum batch token length - Positional embedding modification: apply per-segment positional encoding so each Aᵢ sees positions relative to Q, not to the preceding answers
- Attention mask with custom bias: use a
LowerTriangularCausalMaskWithTensorBiasthat masks out cross-answer attention (Aᵢ ↛ Aⱼ) while preserving Q→A attention for all answers
Additional Optimizations
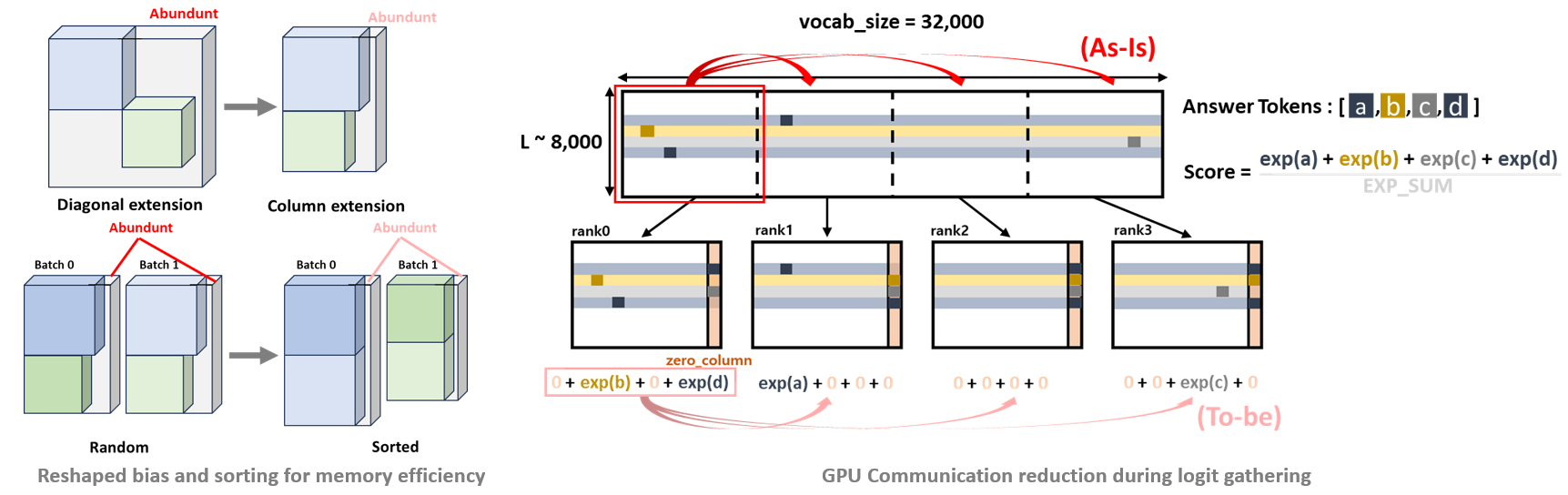
Reshaped Bias Tensor and Kernel Support
The custom attention bias tensor was reshaped from diagonal to column extension form, enabling column-wise kernel computation. Combined with answer token sorting for memory efficiency, this reduces redundant memory accesses in the attention bias computation.
GPU Communication Reduction
In the original 4-GPU model-parallel setup, computing the score for each answer token requires an all-gather of the full logit tensor (vocab size = 32,000) across GPUs. We restructured score gathering so that only the relevant answer token logits are gathered, significantly reducing inter-GPU communication volume (logit all-gather operation optimization).
Results
| Ours (2nd submission) | Ours (1st submission) | lm-eval baseline | |
|---|---|---|---|
| Speedup | 7.86× | 6.86× | 1× |
| Latency (s) | 478.86 | 548.24 | 3763.66 |
- Accuracy fully maintained within std error of LLaMA-33B paper results (accuracy_norm: 82.64 vs. paper 82.80)
- 7.86× speedup over lm-eval baseline; >1.97× speedup over naïve vLLM
Implementation
Built on top of the vLLM framework with the following modifications:
- vLLM wrapper for lm-eval integration (engine, worker, scheduler modified to output logits required for HellaSwag scoring)
layer/attention.pymodified to support meta-pair input metadata and custom attention masking- Score gathering pipeline extended through vLLM worker and engine to collect per-answer logits from the meta-pair output