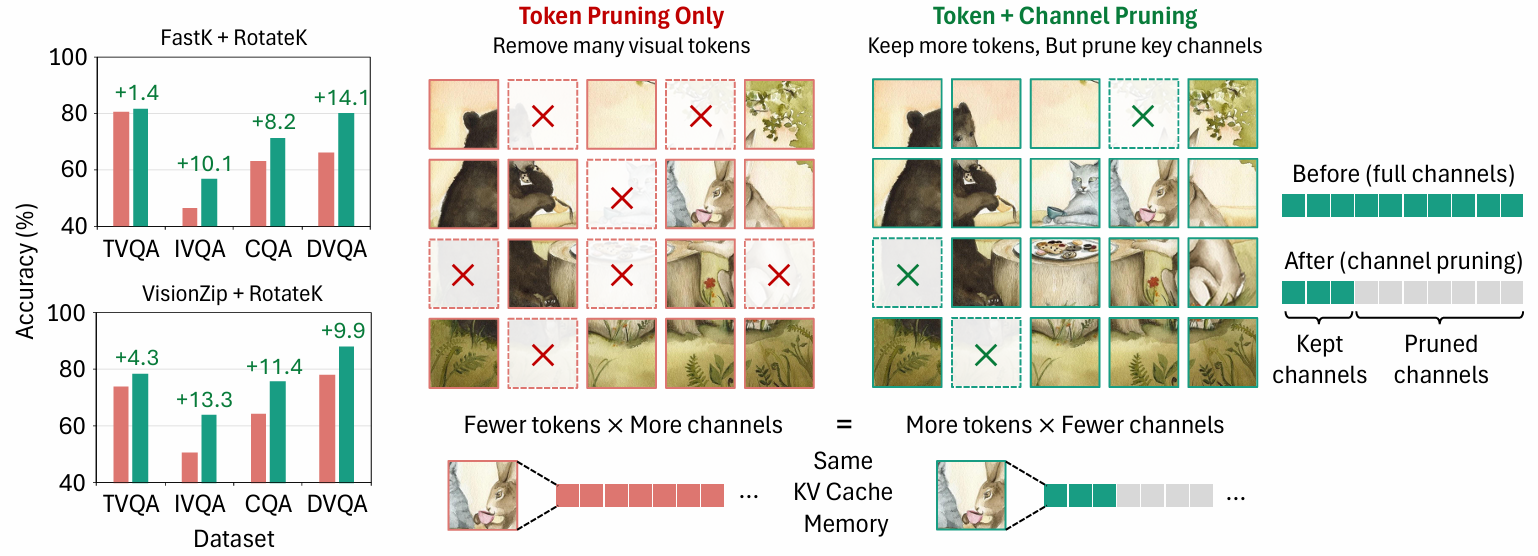
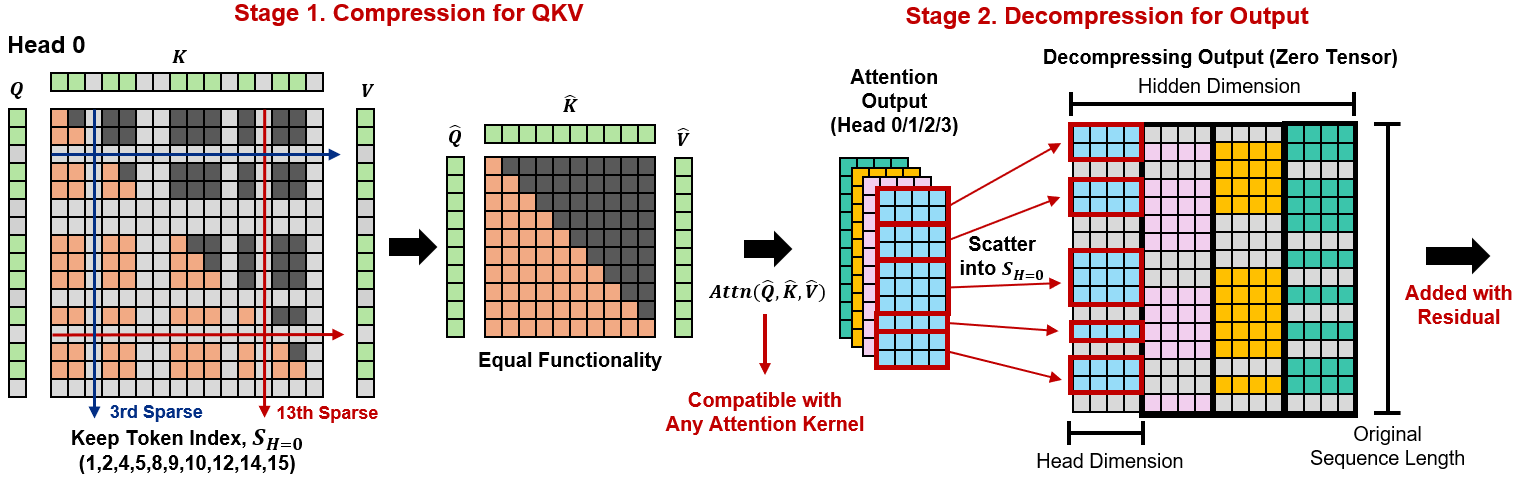
Rotation-Aligned Key Channel Pruning for Efficient Vision-Language Model Inference
Beomseok Kang, Dongwon Jo, Jiwon Song, Donghwee Son, Jae-Joon Kim
arXiv 2026
Paper
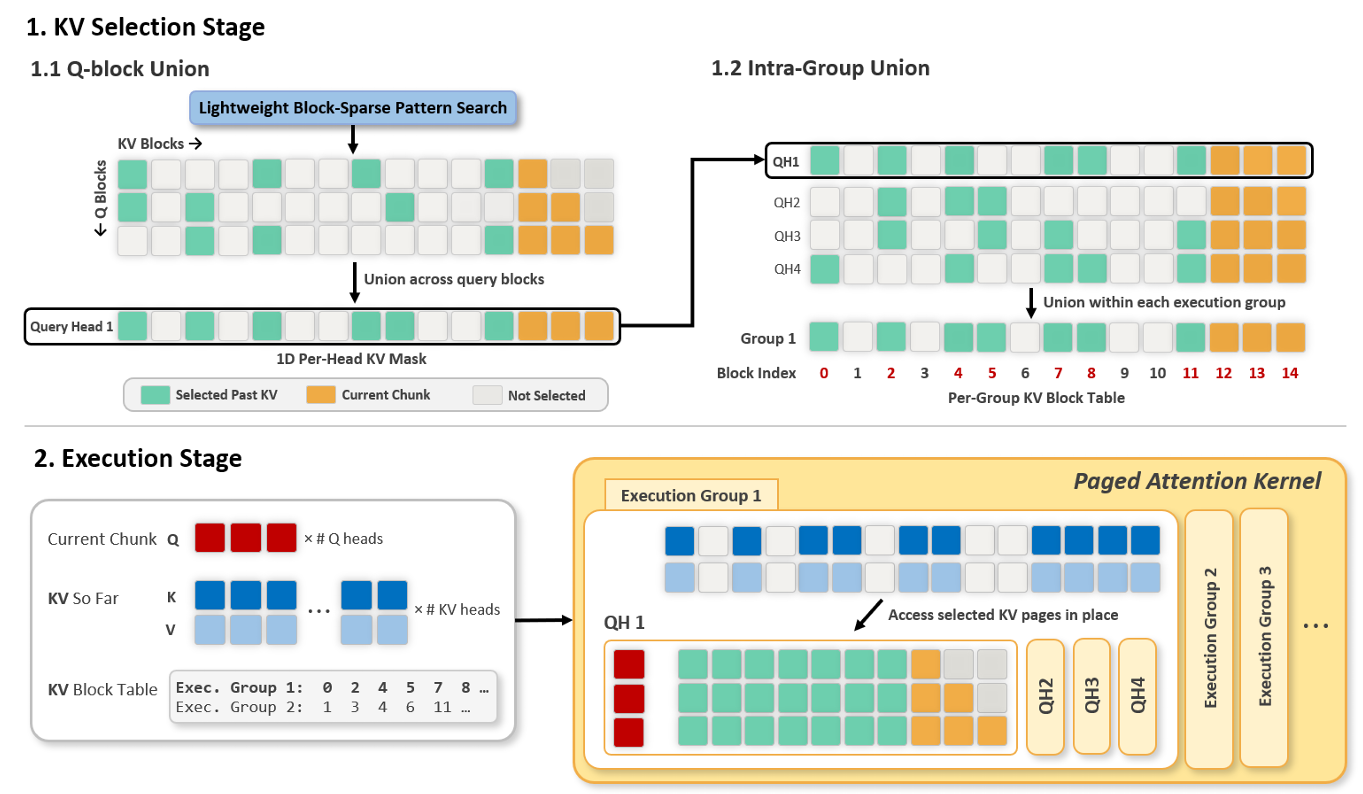
CompactAttention: Accelerating Chunked Prefill with Block-Union KV Selection
Jiwon Song, Dongwon Jo, Beomseok Kang, Jae-Joon Kim
arXiv 2026
Paper Code
Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
Dongwon Jo, Beomseok Kang, Jiwon Song, Jae-Joon Kim
ICML 2026
Paper Code Project
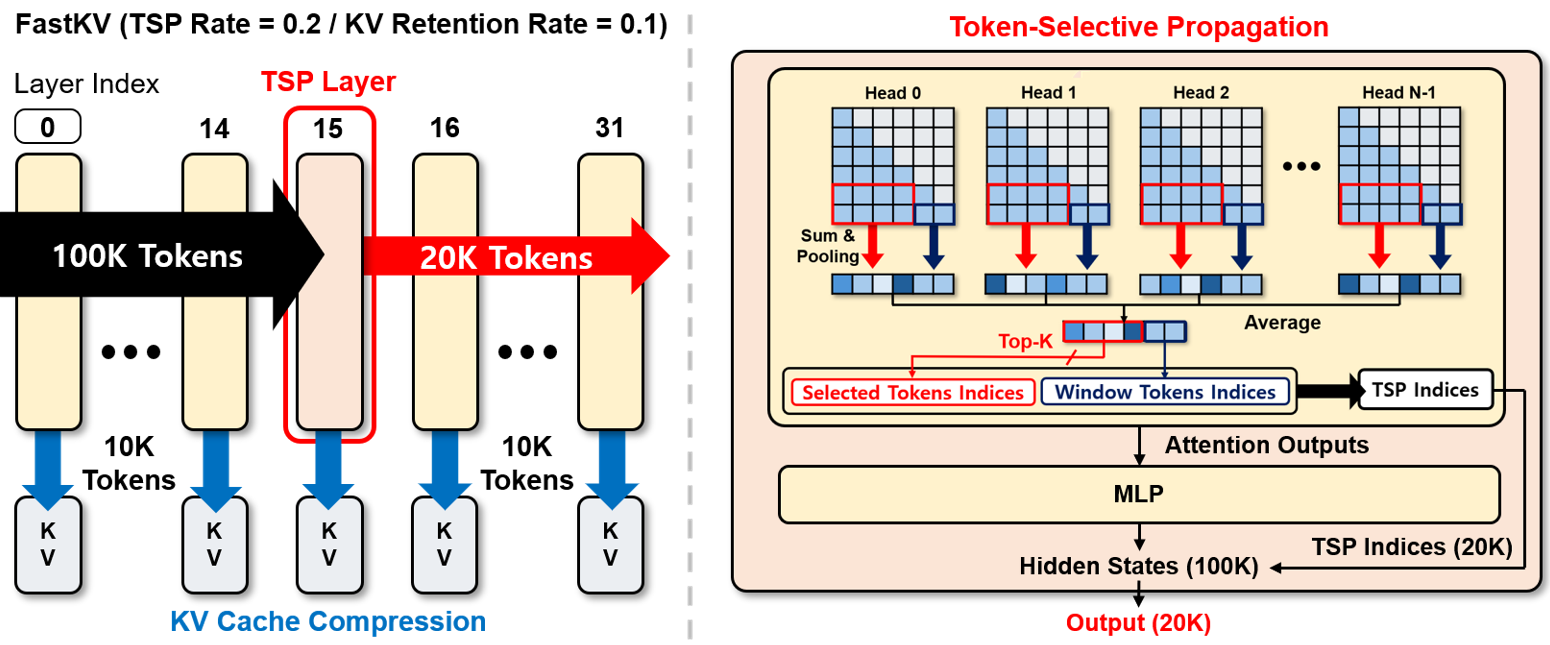
FastKV: Decoupling of Context Reduction and KV Cache Compression for Prefill-Decoding Acceleration
Dongwon Jo*, Jiwon Song*, Yulhwa Kim, Jae-Joon Kim
ACL Findings 2026
Paper Code
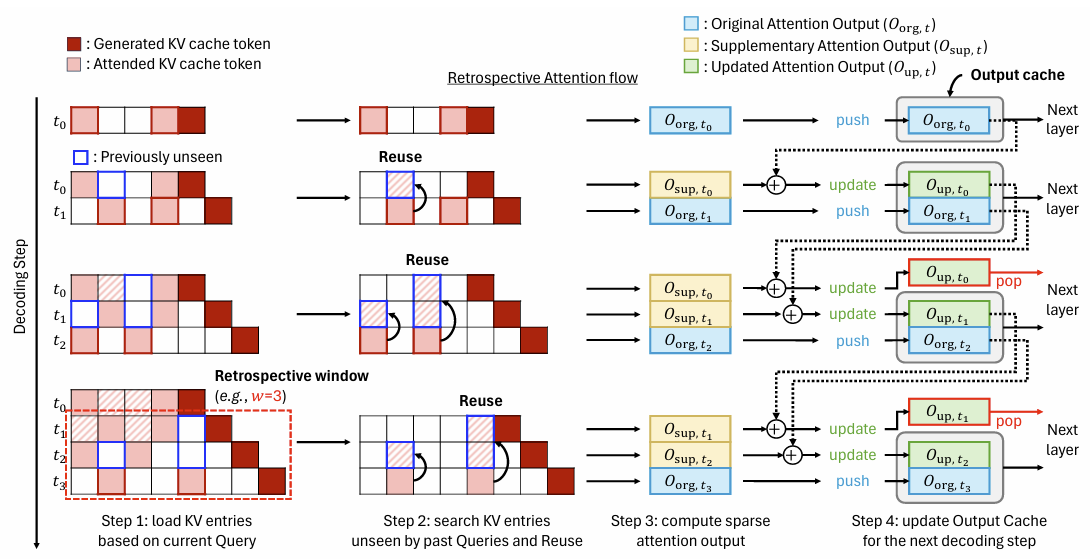
Retrospective Sparse Attention for Efficient Long-Context Generation
Seonghwan Choi*, Beomseok Kang*, Dongwon Jo, Jae-Joon Kim
ICLR 2026
Paper Code
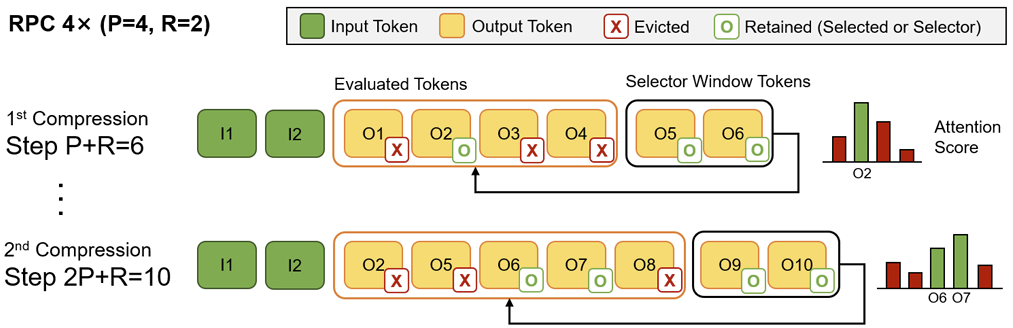
Reasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning
Jiwon Song, Dongwon Jo, Yulhwa Kim, Jae-Joon Kim
NeurIPS 2025
Paper Code
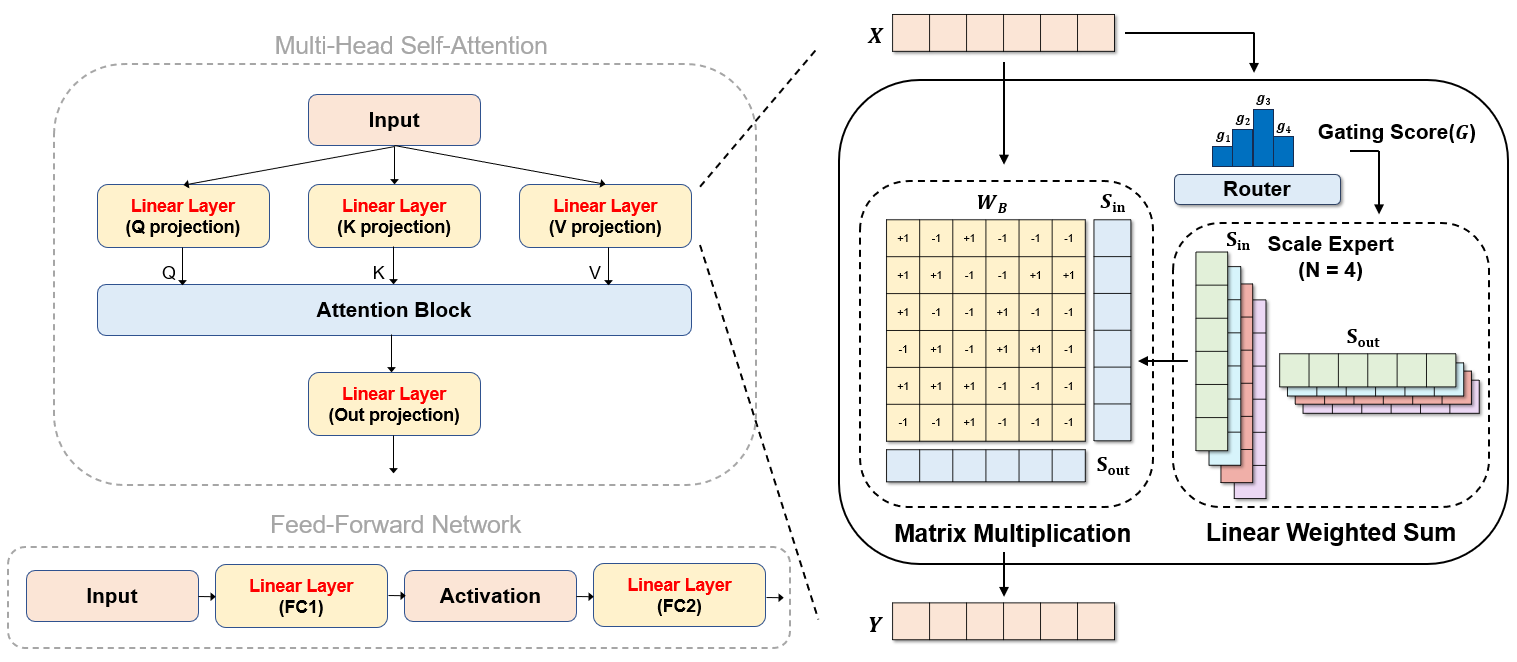
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
Dongwon Jo, Taesu Kim, Yulhwa Kim, Jae-Joon Kim
NeurIPS 2024
Paper Code
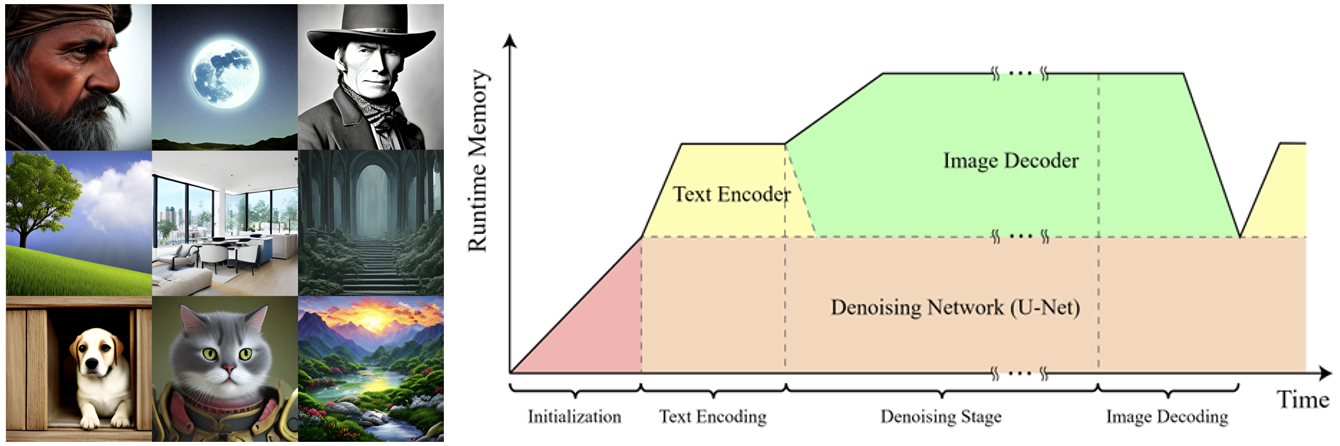
Leveraging Early-Stage Robustness in Diffusion Models for Efficient and High-Quality Image Synthesis
Yulhwa Kim, Dongwon Jo, Hyesung Jeon, Taesu Kim, Daehyun Ahn, Hyungjun Kim, Jae-Joon Kim
NeurIPS 2023
Paper
Squeezing Large-Scaling Diffusion Models for Mobile
Jiwoong Choi, Minkyu Kim, Daehyun Ahn, Taesu Kim, Yulhwa Kim, Dongwon Jo, Hyesung Jeon, Jae-Joon Kim, Hyungjun Kim
ICML Workshop 2023
Paper