
Token Sparse Attention
Published:
Abstract
The quadratic complexity of attention remains the central bottleneck in long-context inference for large language models. Prior acceleration methods either sparsify the attention map with structured patterns or permanently evict tokens at specific layers, which can retain irrelevant tokens or rely on irreversible early decisions despite the layer-/head-wise dynamics of token importance.
We propose Token Sparse Attention, a lightweight and dynamic token-level sparsification mechanism that compresses per-head Q, K, V to a reduced token set during attention and then decompresses the output back to the original sequence, enabling token information to be reconsidered in subsequent layers. Furthermore, Token Sparse Attention exposes a new design point at the intersection of token selection and sparse attention. Our approach is fully compatible with dense attention implementations including Flash Attention, and can be seamlessly composed with existing sparse attention kernels. Experimental results show that Token Sparse Attention consistently improves accuracy–latency trade-off, achieving up to ×3.23 attention speedup at 128K context with less than 1% accuracy degradation.
Demo
🚀 Token Sparse Attention: Push the Limit of Attention
Key Idea
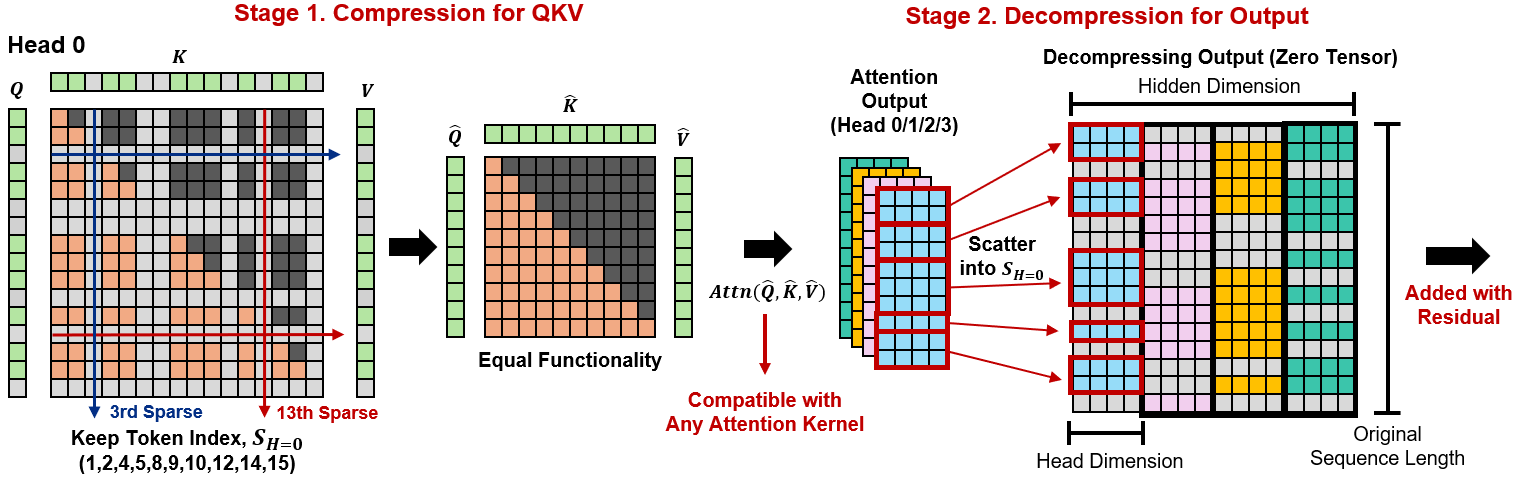
Prior token eviction methods select important tokens in early layers and permanently discard the rest, implicitly assuming that token importance stays stable across layers. In practice, however, token importance shifts substantially from layer to layer, and different attention heads within the same layer prioritize different subsets of tokens.
Token Sparse Attention addresses this with a “Compress and Decompress” design. In Stage 1, each attention head independently selects a subset of tokens and gathers the corresponding Q, K, V rows into compact dense tensors, which are then passed to any standard attention kernel. In Stage 2, the attention output is scattered back into the full sequence layout before the residual connection. Because the full sequence is restored at every layer, no token is permanently removed. Each layer and head can re-select freely from the complete context.
The token selection budget is determined dynamically by Dynamic Token Coverage: a lightweight Triton kernel scores tokens using recent-query attention weights, then identifies the minimal tail of least-important tokens whose cumulative mass exceeds a threshold τ. This allocates sparsity based on the actual attention score distribution rather than a fixed ratio.
Performance Highlights
Token Sparse Attention is designed to be complementary to existing attention methods rather than a replacement. When composed with FlashAttention, Minference, FlexPrefill, SeerAttention, and X-Attention, it consistently improves attention speedup while preserving accuracy within 1% of each baseline.
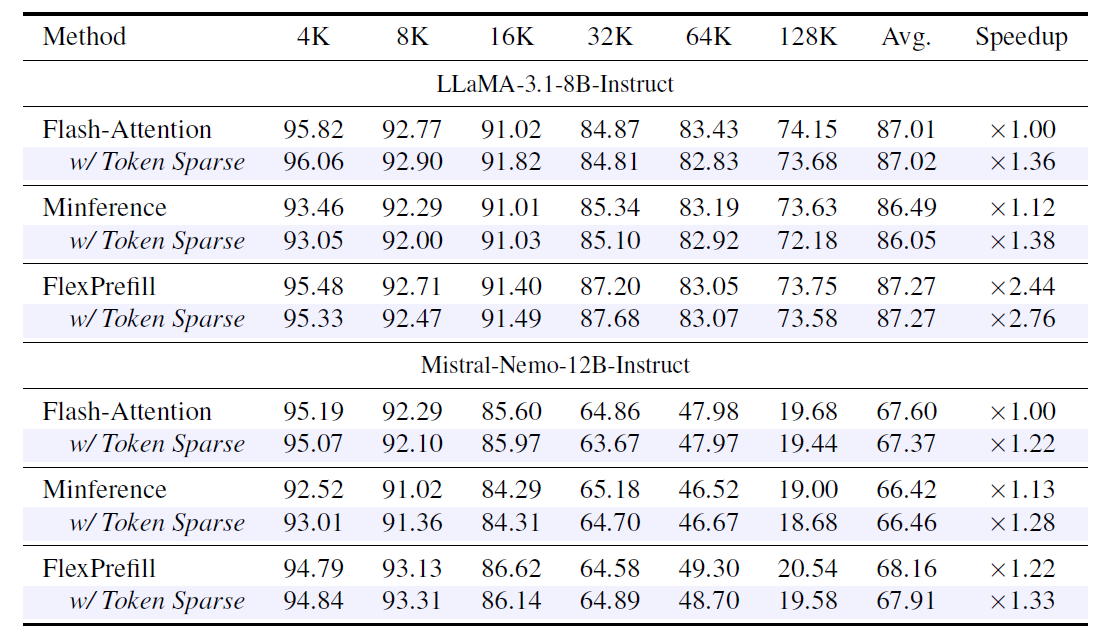
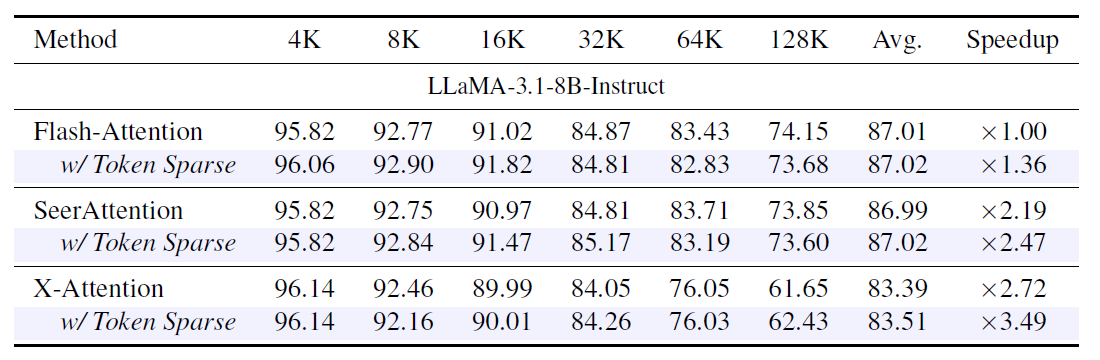
The combination with FlexPrefill is particularly strong. Token Sparse Attention pushes its Pareto frontier outward, reaching ×2.76 attention speedup at the same 87.3% RULER accuracy that FlexPrefill achieves at ×2.44. This gain cannot be replicated by simply tuning FlexPrefill’s hyperparameter. Aggressively increasing sparsity within FlexPrefill alone leads to rapid accuracy degradation, whereas Token Sparse Attention provides additional speedup while keeping accuracy stable. Furthermore, the token coverage parameter τ offers a flexible knob: increasing τ yields higher attention speedups for both FlashAttention and FlexPrefill, with accuracy degradation remaining within 1% even at aggressive sparsity levels.
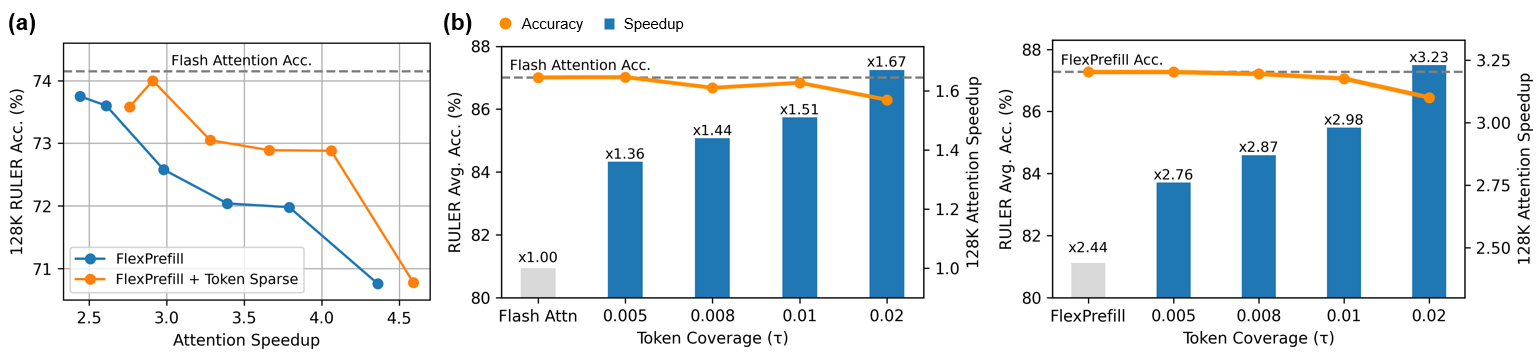
Efficiency Highlights
Attention speedup scales with context length, as longer sequences produce sparser attention distributions. Sparsity within selected layers grows from approximately 17% at 4K to 54% at 128K (τ=0.005), making the method increasingly effective in the long-context regimes where it matters most. The additional overhead introduced by Token Sparse Attention, including token scoring, indexing, and QKV compression and decompression, stays below 11% of total attention latency across all sparsity levels.
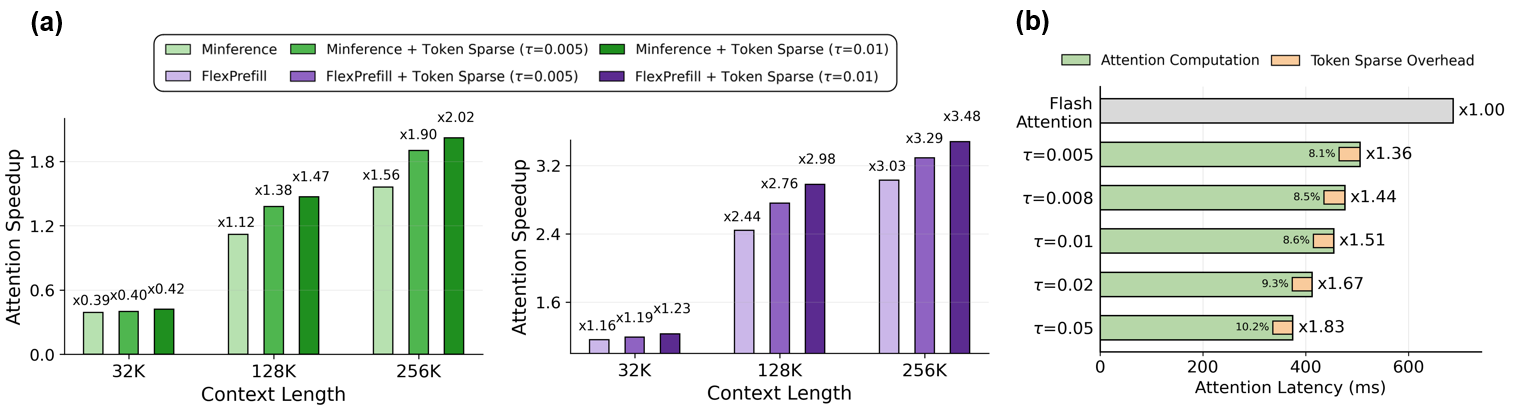
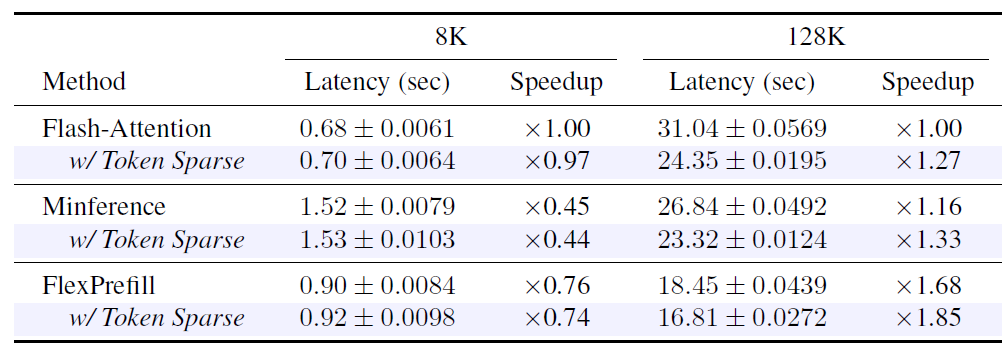
The end-to-end prefill latency gains closely mirror the attention-level speedups at 128K, confirming that attention computation dominates in long-context regimes. At 8K, sparsity is lower and the scoring overhead becomes relatively more visible, but remains small compared to other baselines.
Citation
@article{token_sparse,
title={Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection},
author={Dongwon Jo, Beomseok Kang, Jiwon Song, Jae-Joon Kim},
journal={arXiv preprint arXiv:2602.03216},
year={2026}
}