
Dongwon Jo
I am a Ph.D. student in Electrical & Computer Engineering at Seoul National University, advised by Prof. Jae-Joon Kim. I received my B.S. in Electrical & Electronic Engineering from Yonsei University. My research interests are summarized below.
Research Interests
My primary research aims to make model compression broadly applicable in real-world scenarios. A central theme of my work focuses on reducing the memory and compute costs of Deep Neural Networks (DNNs) that achieve superior accuracy through increased complexity, via algorithm–hardware co-design. Specifically, my research agenda includes:
- Development of DNN accelerators
- Design of hardware-friendly DNNs (e.g., quantized or sparsified models)
- Model compression algorithms for efficient inference
Currently, my research primarily targets generative models, including large language models (LLMs) and diffusion models, with a focus on practical efficiency and scalability. As these models are increasingly deployed in long-context settings, the associated memory and compute costs grow rapidly, creating fundamental barriers to real-world adoption. My work seeks to address these challenges through principled algorithm design, with the goal of making powerful generative models accessible under realistic resource constraints. Ongoing research topics include:
- Quantization and pruning algorithms for LLMs and diffusion models
- KV cache compression and sparse attention for long-context LLM inference
- Kernel-level optimization for high-throughput generative models
*Keywords: Generative Models, Efficient Inference, Model Compression, Algorithm-Hardware Co-design
Selected Publications [Full List]
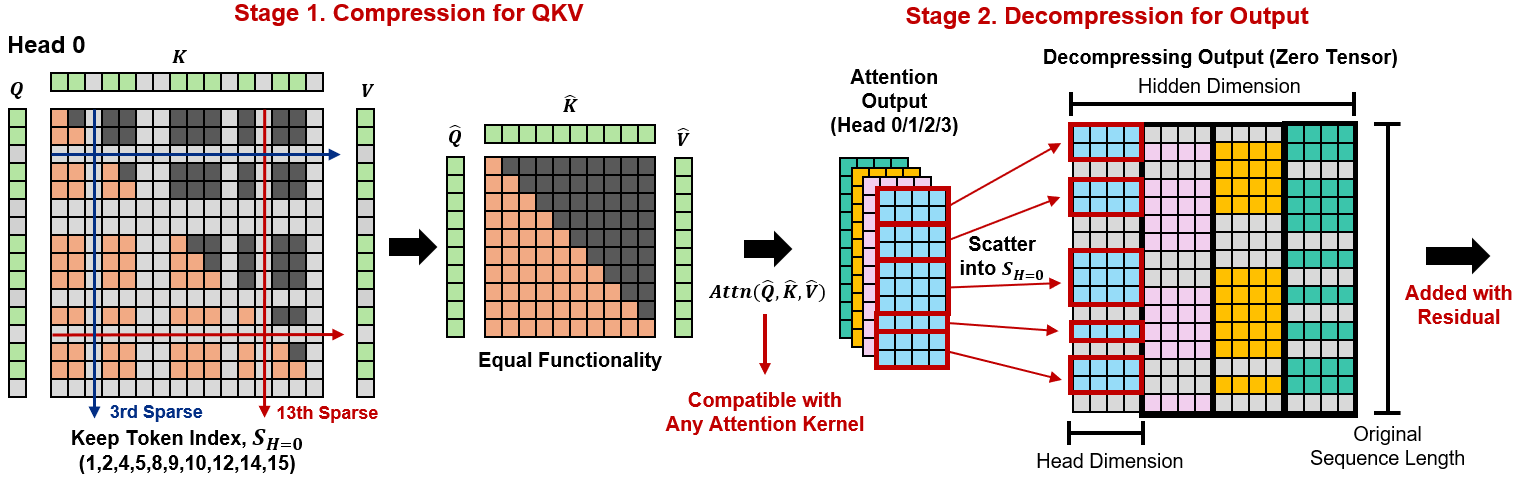
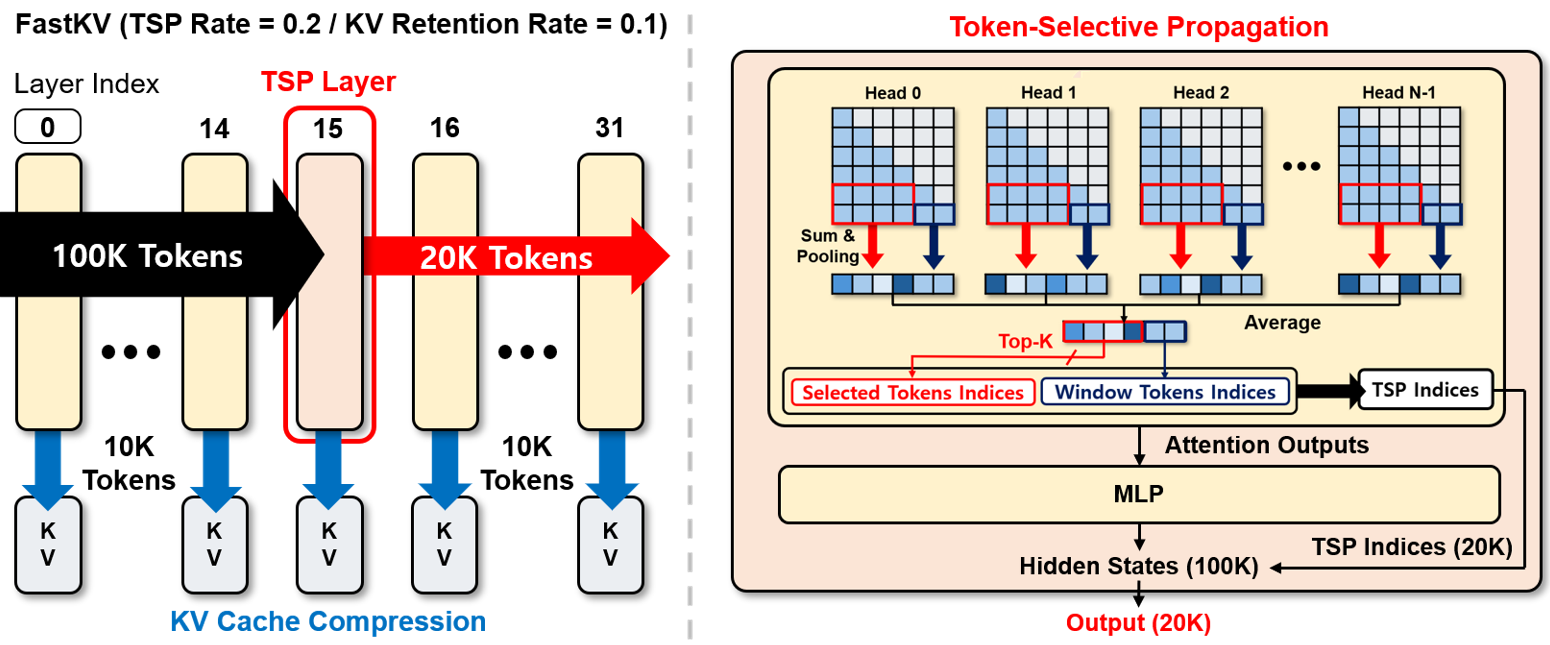
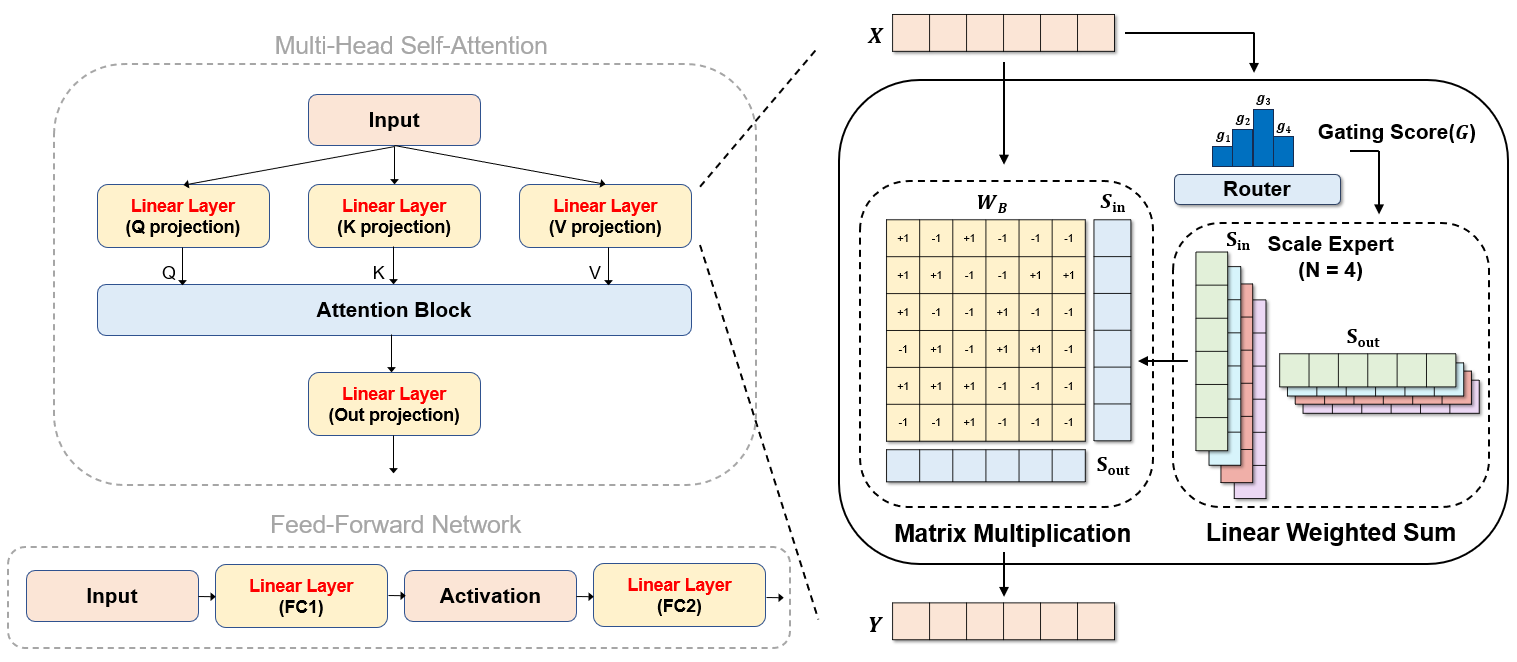
Education
| Seoul National University | Seoul, Korea |
| M.S./Ph.D. in Electrical & Computer Engineering | Sep. 2022 – Present |
| Advisor: Prof. Jae-Joon Kim | |
| Yonsei University | Seoul, Korea |
| B.S. in Electrical & Electronic Engineering | Mar. 2016 – Aug. 2022 |
Work Experiences
| SqueezeBits Inc. | Seoul, Korea |
| Research Intern | Jun. 2022 – Jul. 2022 |
| External Collaborator | Feb. 2023 – May. 2023 |
| Seoul National University | Seoul, Korea |
| Undergraduate Research Intern | Dec. 2021 – Jun. 2022 |
| with Prof. Jae-Joon Kim | |
| Republic of Korea Air Force | Seoul, Korea |
| Sergeant (Military Service) | Jan. 2018 – Dec. 2019 |
Academic Services
| Conference Reviewer | |
| NeurIPS 2025, ICML 2026 (Gold Reviewer), NeurIPS 2026 | |
| Journal Reviewer | |
| IEEE Transactions on Multimedia (TMM) | |
| Transactions on Machine Learning Research (TMLR) | |
Teaching
| Teaching Assistant | Seoul National University |
| 430.201A 002: Digital Logic Design and Lab | Sep. 2022 – Dec. 2022 |